
 Department of Conservation and Recreation
Department of Conservation and Recreation
Conserve. Protect. Enjoy.
Department of Conservation and Recreation





 Table of Contents
Table of ContentsThis section provides an introduction to the procedures DCR-DNH employs in the collection of field data and development of ecological community classifications.
Data Collection
DCR-DNH ecologists are committed to a quantitative approach to vegetation sampling, analysis, and classification using standard field-sampling protocols and numerical methods of data analysis. This emphasis is consistent with both a long history of vegetation investigations in North America and Europe and the U.S. National standards for vegetation classification (Jennings et al. 2009; Peet et al. 2012). Quantitative data explicitly identify differences in abundance and biomass among coexisting plant species. Data collected from sample units of known, standard size provide a consistent basis for comparing stands of disparate vegetation and facilitate sharing of data among users to an extent not possible with mere species lists or data collected from an area of indefinite size. Patterns in composition and structure of ecological communities are dependent on the scale of observation, and a sampling protocol that specifies a particular scale reduces both the likelihood of obscuring patterns across multiple scales and sampler bias in determining whether particular species are recorded. Similarly, numerical methods of analysis offer objective means of generating and evaluating a classification of vegetation and enable the detection of patterns that might otherwise remain unapparent. The collection and analysis of quantitative data to support ecological classification should be viewed neither as panaceas nor ends in their own right. Rather, they are important as tools to further biodiversity conservation, but they provide a critical objective, scientific context for doing so.
Data collection follows standard protocols developed and refined by DCR-DNH over the past 25 years. The fundamental components of these protocols are consistent with sampling techniques employed by other state Natural Heritage programs a wide range of other users (e.g., Peet et al. 1998). For inventory purposes and most contract projects, data are collected from plots 400 m2 in forests and woodlands and 100 m2 in shrubland and herbaceous vegetation. On natural area preserves and other managed areas that require permanently marked plots for long-term monitoring, modular plots up to 1000 m2 that contain nested subplots are sampled more intensively to provide information about vegetation structure, composition, and species richness at multiple spatial scales. In all cases, within each plot all vascular plants present are recorded and the total individual cover of each taxon (defined as the vertical projection of all above-ground biomass) is estimated and assigned to one of nine cover classes representing a range of percentage values. Vegetation structure is assessed by estimating the cover of each woody species at six vertical (height) strata, and stem diameters are measured for all woody stems => 2.5 cm at breast height (1.4 m). A standard set of environmental data is collected, including elevation, aspect, degree of slope, coverage of different types of surface substrate, soil characteristics, and qualitative measures of soil moisture and hydrology. A soil sample is routinely collected from each plot in order to document soil chemistry. All sampling locations are recorded using a global positioning system (GPS). The sampling protocol can include photographic documentation and cursory examination of tree increment cores to deduce stand age and history. Click here for a copy of the DCR-DNH standard plot data collection field form and Instructions (requires the free Adobe reader).
Data Analysis and Classification
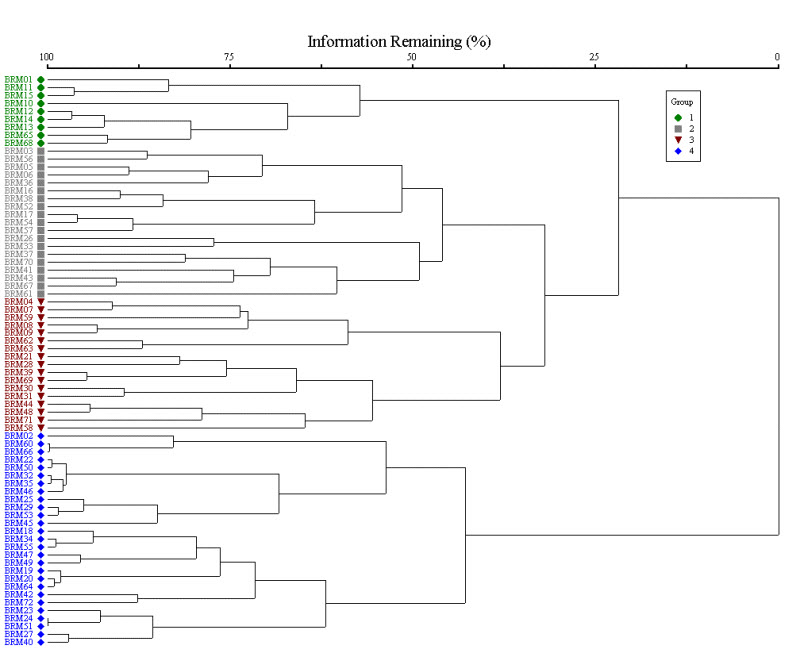
Numerical methods are employed to generate classifications, and emphasis has been placed on circumscribing units across their full distributional range in Virginia and regionally. Adhering to the principle that the recognition of vegetation types should be based on total floristic composition, DCR-DNH ecologists employ cluster analysis to generate classifications. Cluster analysis is a method of numerical classification that evaluates the similarity of quantitative samples and, through an interactive statistical process, fuses into clusters those samples that are most similar. Different types of cluster analysis have been used in vegetation ecology: DCR-DNH ecologists use agglomerative-hierarchical cluster analysis, which starts with each sample in its own group and progressively fuses them into larger groups. Results are displayed as a dendrogram, a tree-like graphic that depicts the resolution of progressively fused groups. As an example, this dendrogram shows the clustering of a 72-plot dataset and the identification of four major groups potentially representing vegetation types.
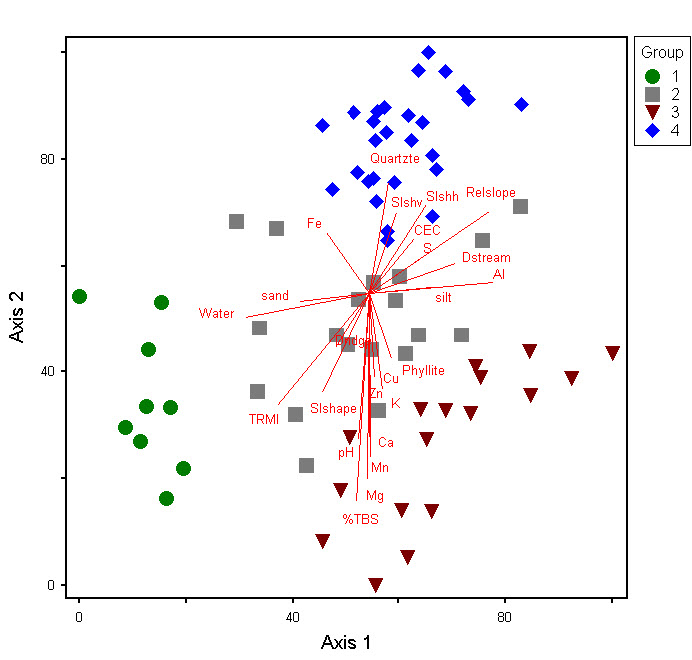
Subsequently, ordination is performed to assess the classification and identify those environmental gradients and site conditions most strongly associated with variation in species composition. Ordination is a multivariate technique that arranges vegetation samples in relation to each other based on compositional similarity and relative species-abundances. Ordination procedures summarize multidimensional data in a reduced coordinate system, extracting those axes that explain the most variation in the data. DCR-DNH ecologists use non-metric multidimensional scaling (NMDS), which is based on indirect gradient analysis that maximizes, to the extent possible, the rank-order (i.e., non-parametric) correlation between inter-sample dissimilarity and inter-sample distance in ordination space. The results of ordination analyses are depicted by diagrams, in which each point represents a plot and the distance between points roughly indicates the degree of compositional similarity. Statistically significant correlations between measured environmental variables and sample coordinates on each axis may be plotted as vectors and overlain on the diagram. The direction of a vector indicates the direction of maximum correlation through ordination space, while vector line lengths are determined by the strength of the correlation. This diagram shows a two-dimensional ordination of the same dataset used to illustrate cluster analysis. Symbols indicate the four groups identified in the dendrogram and significant environmental gradients are plotted.
Both cluster analysis and ordination are implemented in PC-ORD (Version 6; McCune and Mefford 1999-2011). Once potential vegetation types are identified, several summary statistics are calculated to evaluate the consistency and distinctiveness of the type and to aid in selecting nominal taxa. Species-specific values for constancy (the proportion of plots assigned to a vegetation type in which a species occurs), fidelity (the degree to which a species is restricted to a particular type), and mean cover identify the most characteristic and dominant species for each type.
Community Nomenclature
The nomenclature of community types is similar to standards adopted for the USNVC, which uses the scientific names of up to five characteristic species. Although they cannot serve as complete surrogates for detailed descriptions, the names of community types are constructed to facilitate both distinguishing among types and identifying them readily in the field.
Virginia state names use up to six characteristic species.
As a rule, species are listed in descending order of importance and structural position (i.e., overstory species are listed first, followed by understory species, then herbs and low shrubs).
Species used as nominals have high constancy (generally > 60%, but occasionally > 50% if especially diagnostic). Nominal species in the same stratum are separated by a dash (-) while different strata are separated by a slash (/). Species listed in parentheses are less constant, but locally important, in a type. When two species are listed within parentheses, it means that either one or both may be important in a given stand. The typical physiognomy (i.e., forest, woodland, shrubland, etc.) and, for tidal wetland communities, hydrologic regime are included at the end of the formal community type name. A common name equivalent is not a strict translation of Latin names of nominal species, but instead usually refers to the ecological group name and contains a compositional or geographic modifier. As examples,
Zizania aquatica - Pontederia cordata - Peltandra virginica - Persicaria punctata Tidal Herbaceous Vegetation
Freshwater Tidal Marsh (Wild Rice - Mixed Forbs Type)Acer rubrum - Fraxinus americana - Fraxinus nigra - (Betula alleghaniensis) / Veratrum viride - Carex bromoides - Forest
Central Appalachian Basic Seepage Swamp

{kind=link}
{kind=link}